-
flair 모델로 fine-tuning하기프로그래밍/자연어처리 2024. 9. 5. 18:21728x90반응형
flair ner 모델을 사용하다보니 분류 모델로도 사용이 가능하다고 해서 확인해보았다.
flair 모델 훈련 샘플 코드
아래가 훈련 샘플 코드인데 간단해 보인다.
from flair.data import Corpus from flair.datasets import TREC_6 from flair.embeddings import TransformerDocumentEmbeddings from flair.models import TextClassifier from flair.trainers import ModelTrainer # 1. get the corpus corpus: Corpus = TREC_6() # 2. what label do we want to predict? label_type = 'question_class' # 3. create the label dictionary label_dict = corpus.make_label_dictionary(label_type=label_type) # 4. initialize transformer document embeddings (many models are available) document_embeddings = TransformerDocumentEmbeddings('distilbert-base-uncased', fine_tune=True) # 5. create the text classifier classifier = TextClassifier(document_embeddings, label_dictionary=label_dict, label_type=label_type) # 6. initialize trainer trainer = ModelTrainer(classifier, corpus) # 7. run training with fine-tuning trainer.fine_tune('resources/taggers/question-classification-with-transformer', learning_rate=5.0e-5, mini_batch_size=4, max_epochs=10, )샘플 코드에서는 TREC_6 코퍼스를 사용해서 모델 튜닝을 하였다.
TREC_6은 자연어 처리 분야에서 질문 분류(question classification)를 위해 널리 사용되는 데이터셋입니다. 이 데이터셋은 다양한 질문들을 6개의 상위 카테고리로 분류하여 제공합니다.
해당 카테고리는 다음과 같습니다.
ABBR (약어): 약어 또는 축약어에 대한 질문
DESC (설명): 정의나 설명을 요구하는 질문
ENTY (엔티티): 사물, 개념, 사건 등 특정 개체에 대한 질문
HUM (인물): 사람이나 그룹에 대한 질문
LOC (장소): 장소나 위치에 대한 질문
NUM (숫자): 숫자, 수량, 날짜 등 수치 정보를 요구하는 질문
TREC_6 데이터셋은 각 질문이 어떤 유형에 속하는지를 라벨링하여 제공하므로, 머신 러닝 모델이 질문의 유형을 학습하고 예측하는 데 활용됩니다. 이 데이터셋은 자연어 이해, 정보 검색, 챗봇 등 다양한 응용 분야에서 모델의 성능을 평가하는 표준 벤치마크로 사용됩니다. 예를 들어, 질문 "What is the capital of France?"는 LOC 카테고리에 속하며, "Who wrote 'Hamlet'?"은 HUM 카테고리에 속합니다.훈련/테스트 데이터
TREC4에서 사용하는 훈련/테스트 데이터 형식을 확인해보았다.
훈련 데이터(train.txt)

테스트 데이터 (text.txt)
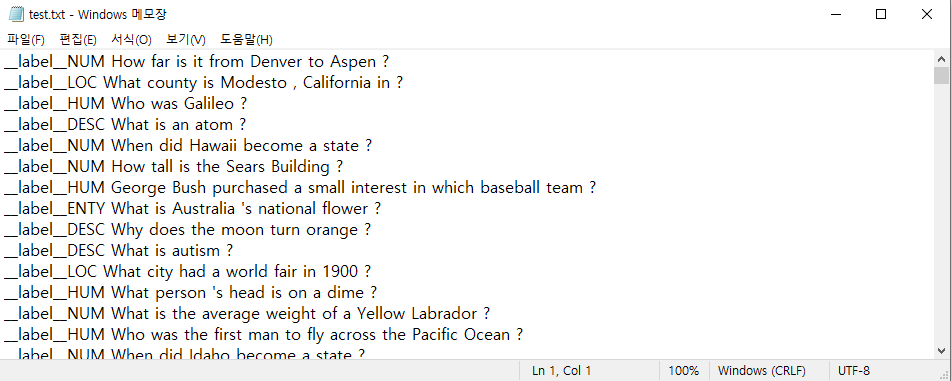
__label__ 다음에 클래스 이름과 해당되는 문장을 넣으면 되는 것 같다.
이렇게 생성된 모델은 trainer에서 지정한 경로에 저장이된다.
resources/taggers/question-classification-with-transformer생성된 모델로 예측하기
이곳에 저장된 파인튜닝된 모델을 불러와서 테스트 하는 방법도 간단하다.
classifier = TextClassifier.load('resources/taggers/question-classification-with-transformer/final-model.pt') # create example sentence sentence = Sentence('Who built the Eiffel Tower ?') # predict class and print classifier.predict(sentence) print(sentence.labels)
자체 데이터셋으로 분류 모델 튜닝하기
샘플 코드가 아니라 내가 생성한 데이터셋으로 분류를 하고싶다면 아래 훈련 모델과 레이블 타입 설정해주는 부분을 본인이 생성한 데이터 셋으로 변경하면 된다.
훈련,dev, 테스트 파일 다 포맷은 동일하다.
# 1. 데이터 경로 설정 data_folder = './data' # 데이터가 위치한 폴더 경로 # 2. 커스텀 코퍼스 생성 corpus: Corpus = ClassificationCorpus(data_folder, train_file='train.txt', dev_file='dev.txt', test_file='test.txt') # 2. what label do we want to predict? label_type = 'class'레이블을 처음에 'question_class'로 했더니 아래와 같은 에러가 나왔었다.
2024-09-05 17:52:21,350 ERROR: You specified label_type='question_class' which is not in this dataset! 2024-09-05 17:52:21,351 ERROR: The corpus contains the following label types: 'class' (in 25 sentences)
확인해보니 그냥 question_type만 class로 변경하면 된다고 한다.
TREC 데이터셋처럼 모든 라벨이 동일한 라벨 타입('class')으로 처리되도록 하기 위해, 위에서 label_type='class'로 설정했습니다. 이렇게 하면 Flair가 모든 라벨을 'class'로 인식하고, 동일한 방식으로 분류 작업을 수행합니다.만약 아래와 같은 데이터 에러가 나온다면 파일이 제대로 위치하는지 확인한다.
파일이 있다면 텍스트 파일에서 __label__로 시작하는 라벨이 있어야 하며, 그 뒤에 해당 텍스트가 있는지 확인한다.
corpus: Corpus = ClassificationCorpus(data_folder, ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\Lib\site-packages\flair\datasets\document_classification.py", line 117, in __init__ super().__init__(train, dev, test, name=str(data_folder), sample_missing_splits=sample_missing_splits)
File "D:\Lib\site-packages\flair\data.py", line 1361, in __init__ raise RuntimeError("No data provided when initializing corpus object.")
RuntimeError: No data provided when initializing corpus object.# 3. create the label dictionary label_dict = corpus.make_label_dictionary(label_type=label_type) # 4. initialize transformer document embeddings (many models are available) document_embeddings = TransformerDocumentEmbeddings('distilbert-base-uncased', fine_tune=True) # 5. create the text classifier classifier = TextClassifier(document_embeddings, label_dictionary=label_dict, label_type=label_type)textclsssifer 옵션 설명

flair classifier 옵션 훈련 옵션은 샘플 코드와 동일하게 진행하였다. 샘플에 나오지 않는 옵션들은 위 주석을 참고하였다.
튜닝 결과 확인하기
Results:
- F-score (micro) 0.9701
- F-score (macro) 0.8653
- Accuracy 0.9701
By class:
precision recall f1-score support
클래스1 0.9615 1.0000 0.9804 125
클래스2 1.0000 1.0000 1.0000 33
클래스3 1.0000 0.4444 0.6154 9
accuracy 0.9701 167
macro avg 0.9872 0.8148 0.8653 167
weighted avg 0.9712 0.9701 0.9646 167각 용어의 의미
Precision: 모델이 정답(Positive)으로 예측한 샘플 중 실제로 정답인 샘플의 비율입니다.
Recall: 실제 정답 샘플 중 모델이 올바르게 정답으로 예측한 비율입니다.
F1-score: Precision과 Recall의 조화 평균으로, 두 지표 간의 균형을 측정합니다.
Support: 각 클래스에 속하는 실제 샘플의 수입니다.클래스별 분석
클래스1:
Precision: 0.9615 → 모델이 " 클래스1 "로 예측한 샘플 중 약 96.15%가 실제로 " 클래스1 "입니다.
Recall: 1.0000 → 실제 " 클래스1 " 샘플 중 100%가 올바르게 예측되었습니다.
F1-score: 0.9804 → Precision과 Recall의 조화 평균으로 매우 높은 성능을 나타냅니다.
Support: 125 → 테스트 데이터에서 " 클래스1 " 클래스에 속한 샘플은 125개입니다.
클래스2 :
Precision: 1.0000 → 모델이 " 클래스2 "로 예측한 샘플이 모두 정확하게 예측되었습니다.
Recall: 1.0000 → 실제 " 클래스2 " 샘플 중 100%가 올바르게 예측되었습니다.
F1-score: 1.0000 → Precision과 Recall이 모두 100%이므로 F1-score도 100%입니다.
Support: 33 → " 클래스2 " 클래스에 속한 테스트 샘플은 33개입니다.클래스3:
Precision: 1.0000 → 모델이 " 클래스3 "로 예측한 샘플은 모두 정확하게 예측되었습니다.
Recall: 0.4444 → 실제 " 클래스3 " 샘플 중 약 44.44%만 올바르게 예측되었습니다. 이는 소수의 " 클래스3 " 샘플을 모델이 놓쳤을 가능성이 있음을 나타냅니다.
F1-score: 0.6154 → Precision은 높지만 Recall이 낮기 때문에 F1-score는 61.54%로, 다른 클래스에 비해 성능이 떨어집니다.
Support: 9 → 테스트 데이터에서 " 클래스3 " 클래스에 속한 샘플은 9개입니다.전체 성능
Accuracy: 0.9701 → 모델이 전체 167개의 샘플 중 97.01%를 정확하게 분류했습니다.
Macro avg (균등 가중치 평균)
Precision: 0.9872 → 각 클래스별 precision의 평균.
Recall: 0.8148 → 각 클래스별 recall의 평균, 특히 "클래스3" 클래스의 낮은 recall이 이 값에 영향을 미칩니다.
F1-score: 0.8653 → 각 클래스별 F1-score의 평균.
Macro avg는 각 클래스의 성능을 동일한 중요도로 고려합니다.
Weighted avg (샘플 수에 따른 가중 평균)
Precision: 0.9712
Recall: 0.9701
F1-score: 0.9646
Weighted avg는 클래스별 샘플 수에 비례하여 평균을 냅니다. "클래스1" 클래스가 샘플 수가 많기 때문에 weighted avg는 이 클래스에 크게 영향을 받습니다.결론
클래스1와 클래스2는 매우 높은 성능을 보이지만, 클래스3는 Recall이 낮아 일부 샘플을 놓치고 있습니다.
클래스3는 데이터가 적고 불균형 문제로 인해 성능이 떨어지는 것으로 보입니다. 이 클래스에 대한 Recall을 높이기 위해서는 더 많은 데이터 확보나 가중치 조정과 같은 불균형 문제 해결 방법을 적용할 필요가 있습니다.오버피팅이 의심되긴 해서 일단 데이터를 늘리면서 좀 더 튜닝을 진행해봐야겠다.
사용이 간단하고 튜닝 성능도 나쁘지 않아서 앞으로도 자주 사용할 것 같다.
참고
https://github.com/flairNLP/flair/blob/master/flair/models/text_classification_model.py
https://flairnlp.github.io/docs/tutorial-training/how-to-train-text-classifier
728x90반응형'프로그래밍 > 자연어처리' 카테고리의 다른 글
pytorch 설치하기 (1) 2024.09.19 한국어 ner 시작하기 - pytorch-bert-crf-ner 사용후기 (0) 2024.08.26 한국어 NER 시작하기 - flair 사용방법 (0) 2024.08.23 azure openai 사용하여 임베딩 변환하기 (0) 2024.08.20 fasttext 사용하여 임베딩 하기 (1) 2022.09.24